1块显卡+几行代码:大模型训练提速40%!
不得不说,为了让更多人能用上大模型,技术圈真是各出奇招!
模型不够开放?有人自己上手搞免费开源版。
比如最近风靡全网的DALL·EMini,Meta开放的OPT-175B(OpenPretrainedTransformer)。
都是通过复刻的方式,让原本不够open的大模型,变成人人可用。
还有人觉得模型太大,个人玩家很难承受起天价成本。
所以提出异构内存、并行计算等方法,让大模型训练加速又降本。
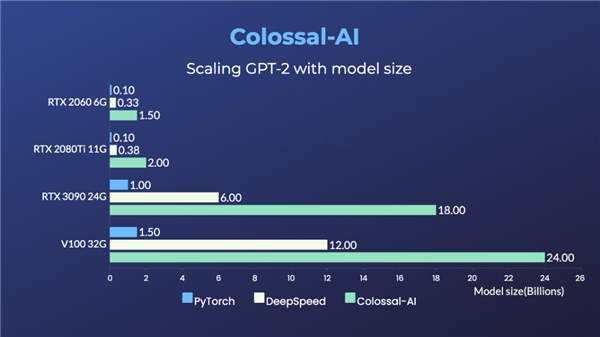
比如开源项目Colossal-AI,前不久刚实现了让一块NVIDIARTX3090就能单挑180亿参数大模型。
而在这两天,他们又来了一波上新:
无缝支持HuggingFace社区模型,只需添加几行代码,就能实现大模型的低成本训练和微调。

要知道,HuggingFace作为当下最流行的AI库之一,提供了超过5万个AI模型的实现,是许多AI玩家训练大模型的首选。
而Colossal-AI这波操作,是让公开模型的训练微调变得更加切实可行。
并且在训练效果上也有提升。
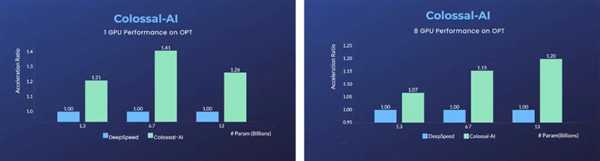
单张GPU上,相比于微软的DeepSpeed,使用Colossal-AI的自动优化策略,最快能实现40%的加速。
而PyTorch等传统深度学习框架,在单张GPU上已经无法运行如此大的模型。
对于使用8张GPU的并行训练,仅需在启动命令中添加-nprocs8就能实现。
这波下来,可以说是把个人AI玩家需要考虑的成本、效率、实操问题,都拿捏住了~
无需修改代码逻辑
光说不练假把式。
下面就以OPT为例,详细展开看看Colossal-AI的新功能到底怎么用。
OPT,全称为OpenPretrainedTransformer。
它由MetaAI发布,对标GPT-3,最大参数量可达1750亿。
最大特点就是,GPT-3没有公开模型权重,而OPT开源了所有代码及权重。
因此,每一位开发者都能在此基础上开发个性化的下游任务。
下面的举例,就是根据OPT提供的预训练权重,进行因果语言模型(CasualLanguageModelling)的微调。
主要分为两个步骤:
1、添加配置文件
2、运行启动
第一步,是根据想进行的任务添加配置文件。
比如在一张GPU上,以异构训练为例,只需在配置文件里加上相关配置项,并不需要更改代码的训练逻辑。
比如,tensor_placement_policy决定了异构训练的策略,参数可以为CUDA、CPU及auto。
每个策略的优点不同、适应的情况也不一样。
CUDA:将全部模型参数都放置于GPU上,适合不offload时仍然能进行训练的传统场景。
CPU:将模型参数都放置在CPU内存中,仅在GPU显存中保留当前参与计算的权重,适合超大模型的训练。
auto:根据实时的内存信息,自动决定保留在GPU显存中的参数量,这样能最大化利用GPU显存,同时减少CPU-GPU之间的数据传输。
对于普通用户来说,使用auto策略是最便捷的。
这样可以由Colossal-AI自动化地实时动态选择最佳异构策略,最大化计算效率。
fromcolossalai.zero.shard_utilsimportTensorShardStrategy
zero=dict(model_config=dict(shard_strategy=TensorShardStrategy(),
tensor_placement_policy="auto"),
optimizer_config=dict(gpu_margin_mem_ratio=0.8))
第二步,是在配置文件准备好后,插入几行代码来启动新功能。
首先,通过一行代码,使用配置文件来启动Colossal-AI。
Colossal-AI会自动初始化分布式环境,读取相关配置,然后将配置里的功能自动注入到模型及优化器等组件中。
colossalai.launch_from_torch(config='./configs/colossalai_zero.py')
然后,还是像往常一样定义数据集、模型、优化器、损失函数等。
比如直接使用原生PyTorch代码,在定义模型时,只需将模型放置于ZeroInitContext下初始化即可。
在这里,使用的是HuggingFace提供的OPTForCausalLM模型以及预训练权重,在Wikitext数据集上进行微调。
withZeroInitContext(target_device=torch.cuda.current_device(),
shard_strategy=shard_strategy,
shard_param=True):
model=OPTForCausalLM.from_pretrained(
'facebook/opt-1.3b'
config=config
接下来,只需要调用colossalai.initialize,便可将配置文件里定义的异构内存功能统一注入到训练引擎中,即可启动相应功能。
engine,train_dataloader,eval_dataloader,lr_scheduler=colossalai.initialize(model=model,
optimizer=optimizer,
criterion=criterion,
train_dataloader=train_dataloader,
test_dataloader=eval_dataloader,
lr_scheduler=lr_scheduler)
还是得靠GPU+CPU异构
而能够让用户实现如上“傻瓜式”操作的关键,还是AI系统本身要足够聪明。
发挥核心作用的是Colossal-AI系统的高效异构内存管理子系统Gemini。
它就像是系统内的一个总管,在收集好计算所需的信息后,动态分配CPU、GPU的内存使用。
具体工作原理,就是在前面几个step进行预热,收集PyTorch动态计算图中的内存消耗信息。
在预热结束后,计算一个算子前,利用收集的内存使用记录,Gemini将预留出这个算子在计算设备上所需的峰值内存,并同时从GPU显存移动一些模型张量到CPU内存。
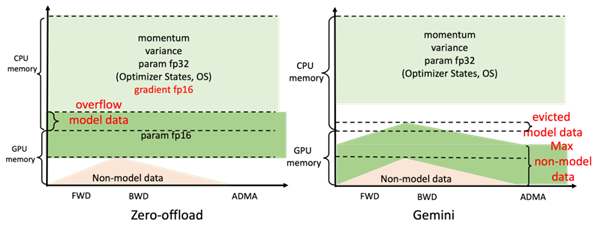
Gemini内置的内存管理器给每个张量都标记一个状态信息,包括HOLD、COMPUTE、FREE等。
然后,根据动态查询到的内存使用情况,不断动态转换张量状态、调整张量位置。
带来的直接好处,就是能在硬件非常有限的情况下,最大化模型容量和平衡训练速度。
要知道,业界主流方法ZeRO(ZeroReduencyOptimizer),尽管也利用CPU+GPU异构内存的方法,但是由于是静态划分,还是会引起系统崩溃、不必要通信量等问题。
而且,使用动态异构CPU+GPU内存的办法,还能用加内存条的办法来扩充内存。
怎么也比买高端显卡划算多了。

目前,使用Colossal-AI的方法,RTX20606GB普通游戏本能训练15亿参数模型;RTX309024GB主机直接单挑180亿参数大模型;TeslaV10032GB连240亿参数都能拿下。
除了最大化利用内存外,Colossal-AI还使用分布式并行的方法,让训练速度不断提升。
它提出同时使用数据并行、流水并行、2.5维张量并行等复杂并行策略。